標準偏差でクラス間のバラツキを見る
今回は、クラス分けしたグループ間のバラツキ具合を、標準偏差を用いて見ます。
5教科の成績表をもとに100人を4つにクラス分けする方法を考えています。1回目、2回目、3回目につづく、シリーズ4回目。
クラス分けをする際、人数は同じに、成績表の合計点と教科ごとでも適度に分散し平均的になるように分けたい。
「標準偏差」を用いればバラツキが抑えられるのではないか。
バラツキが大きいと標準偏差も大きくなりますので、標準偏差が小さくなるようにクラス分け出来れば目標に近づけるはず・・・
【クラス分けの方法について】
方法の手順として、
- データフレームをランダムにシャッフルして、クラス番号を順に割り振る
- クラスごとで教科や合計等の平均値を出す
- クラス間で平均値の標準偏差を出しバラツキを見る
- クラス間の教科や合計の標準偏差の更に標準偏差を出し、その最小値を探す
でやってみようと思います。上手く行くかは・・・
前回は①をやりましたので、今回は上の②と③。
クラスごとで平均値を出し、クラス間のバラツキを見るために標準偏差を出します。
【実行環境】
- Windows10
- WSL:Ubuntu:Anaconda4.10.1
- Python3.8.10
- Jupyter Notebook6.4.0
- 使用ライブラリ
- numpy1.20.2、pandas1.2.4、matplotlib3.3.4、scikit-learn0.24.2、japanize-matplotlib(グラフの日本語表示用)
Anacondaをインストールすると今回使うライブラリは最初から全部入っているようなので(japanize-matplotlib以外は)インストールは不要です。
入ってないようならcondaやpipで
$ pip install notebook numpy pandas matplotlib sklearn japanize-matplotlib
など環境に合わせてインストールしておきます。
成績表を生成する
前回までと同様に、国・数・社・理・英、各100点満点のテストの成績表を100人分、一様分布のランダムな値で生成します。
5教科の合計点を個人ごとに算出し、その値の大きい順から順位付けを行います。
成績表を行でランダムにシャッフルし、4つのクラスに分けクラス番号を割り振ります。
# 成績表の生成import numpy as np import pandas as pd import sklearn np.random.seed(0) # ランダムの固定# 教科ごとのランダムな配列を生成 (漢字を変数として使用国 = np.random.randint(0,101,100) 数 = np.random.randint(0,101,100) 社 = np.random.randint(0,101,100) 理 = np.random.randint(0,101,100) 英 = np.random.randint(0,101,100) # 成績表データフレームの作成 df = pd.DataFrame({ "国語" : 国, "数学" : 数, "社会" : 社, "理科" : 理, "英語" : 英 }) # 5教科合計列の追加 df['合計'] = df.sum(axis=1) # 合計点順位列の追加 (降順で順位付け、同一順位は最小値を取る、順位を整数値に変換) df['順位'] = df['合計'].rank(method='min', ascending=False).astype('int') # 成績表dfの行をランダムに入れ替える df_shuffled = sklearn.utils.shuffle(df, random_state=0) # random_stateで乱数固定# クラス番号列を追加 df_shuffled_class = df_shuffled.copy() # コピー df_shuffled_class['クラス番号'] = np.repeat(np.array([0,1,2,3]), 25) # 表示 df_shuffled_class
| 国語 | 数学 | 社会 | 理科 | 英語 | 合計 | 順位 | クラス番号 | |
|---|---|---|---|---|---|---|---|---|
| 26 | 20 | 59 | 86 | 46 | 8 | 219 | 71 | 0 |
| 86 | 47 | 75 | 61 | 11 | 70 | 264 | 39 | 0 |
| 2 | 64 | 69 | 31 | 93 | 53 | 310 | 17 | 0 |
| 55 | 0 | 38 | 23 | 87 | 57 | 205 | 79 | 0 |
| 75 | 0 | 66 | 33 | 83 | 36 | 218 | 72 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 96 | 23 | 83 | 35 | 51 | 97 | 289 | 24 | 3 |
| 67 | 65 | 98 | 39 | 14 | 83 | 299 | 21 | 3 |
| 64 | 58 | 2 | 27 | 25 | 9 | 121 | 95 | 3 |
| 47 | 74 | 43 | 53 | 56 | 100 | 326 | 8 | 3 |
| 44 | 57 | 36 | 51 | 67 | 23 | 234 | 61 | 3 |
100 rows × 8 columns
以上、前回までの内容。
標準偏差(standard deviation)をクラスごとで出す
ここからが今回の内容です。
まず、↑のデータフレームに対して、Pandasのgroupby().mean()メソッドでクラス別の平均点を算出します。
次に、算出された各クラスごとの平均点に対し、std()メソッドで標準偏差を出します。
とりあえず、そこまでやります。
# クラスごとの平均値を出す df_shuffled_class.groupby('クラス番号').mean()
| 国語 | 数学 | 社会 | 理科 | 英語 | 合計 | 順位 | |
|---|---|---|---|---|---|---|---|
| クラス番号 | |||||||
| 0 | 34.68 | 52.76 | 44.60 | 63.40 | 48.20 | 243.64 | 54.64 |
| 1 | 51.64 | 47.36 | 48.24 | 44.16 | 44.12 | 235.52 | 55.16 |
| 2 | 57.68 | 53.00 | 44.52 | 57.20 | 47.80 | 260.20 | 42.72 |
| 3 | 51.00 | 42.88 | 47.32 | 46.12 | 57.16 | 244.48 | 48.36 |
# 平均値の標準偏差を出し、バラツキを見る df_shuffled_class.groupby('クラス番号').mean().std()
国語 9.850963
数学 4.840165
社会 1.896910
理科 9.146336
英語 5.539868
合計 10.317364
順位 5.877913
dtype: float64
これらの値はクラス間の各列(科目など)における標準偏差を示しています。
「社会」の標準偏差は1.89になっており、他の科目と比べて低い。ということは「社会」はクラス間のバラツキが抑えられていることを示しています。
↑で表示した平均値のデータフレームを見ると「社会」の列はクラスごとで平均値の差がなく、44.52~48.24の狭い範囲に収まっている。
一方、「国語」の標準偏差は9.85で比較的大きい。↑の平均値のデータフレームの値も34.68~57.68の広い範囲。クラス間で差があり、バラついたクラス分けになっているといえる。
「合計」の標準偏差は更に大きく10.31なので、クラス間の学力差のバラツキが大きいことを示しています。
「国語」~「順位」までの列で、クラス間の標準偏差のさらに標準偏差を出してみる。
最終的にこれが小さければ、理想的に平均化したクラス分けと言えるんじゃないか。
# 全体的な標準偏差を算出 df_shuffled_class.groupby('クラス番号').mean().std().std()
3.0957634438346426
この値が小さければ、教科別でも合計点平均でもクラス間の差がないということになる。
これまで行ってきた、
ランダムに行シャッフル
⇒ クラス番号付け
⇒ クラスごと平均値の算出
⇒ クラス間の標準偏差を算出 ⇒ 最終的な全体の標準偏差を算出
の工程を何度か繰り返し、最終的に出した全体的な標準偏差が最も小さくなるクラス分けを探せば、最もバランスの取れたクラス分けとなる。はず。たぶん・・・
最終的な標準偏差を求めるまでの工程を関数で書いて、その関数をfor文でぶん回し、グラフ描けばなんか見えてくるだろう。
ええい!
クラス分け工程の関数化と実行
# 成績表の生成import numpy as np import pandas as pd import sklearn np.random.seed(0) # ランダムの固定##### 成績表の生成関数 #####defmake_report(): # 教科ごとのランダムな配列を生成 (漢字を変数として使用国 = np.random.randint(0,101,100) 数 = np.random.randint(0,101,100) 社 = np.random.randint(0,101,100) 理 = np.random.randint(0,101,100) 英 = np.random.randint(0,101,100) # 成績表データフレームの作成 df = pd.DataFrame({"国語":国, "数学":数, "社会":社, "理科":理, "英語":英}) # 5教科合計列の追加 df['合計'] = df.sum(axis=1) # 合計点順位列の追加 (降順で順位付け、同一順位は最小値を取る、順位を整数値に変換) df['順位'] = df['合計'].rank(method='min', ascending=False).astype('int') # 戻り値return df ##### クラス分け結果を標準偏差で表す関数 ##### defoutput_std(df): # 成績表dfの行をランダムに入れ替える df_shuffled = sklearn.utils.shuffle(df) # randam_stateは除外# クラス番号列を追加し、ランダムにクラス分けしたdf_shuffled_classを生成 df_shuffled_class = df_shuffled.copy() # コピー df_shuffled_class['クラス番号'] = np.repeat(np.array([0,1,2,3]), 25) # クラス分け後のデータフレームと、その平均値データフレーム、その時の最終的な評価を返す mean = df_shuffled_class.groupby('クラス番号').mean() return df_shuffled_class, mean_df, mean_df.std().std()
できたので、ひとまず2回だけ工程を繰り返してクラス分け結果とバラツキ具合の標準偏差をみてみる。
##### 実行 ###### 成績表の生成 df = make_report() # クラス分けを2回繰り返すfor i inrange(2): # 元の成績表dfから、クラス分け後df、その平均値df、標準偏差の分解 classed_df, mean_df, _std = output_std(df) # 表示print(f'【試行{i+1}回目】') print(classed_df) print('-'*40) print(mean_df) print('-'*40) print("標準偏差 : ", _std) print('\n', '='*40)
【試行1回目】
国語 数学 社会 理科 英語 合計 順位 クラス番号
94 10 68 24 79 31 212 71 0
70 79 91 12 53 41 276 35 0
86 36 31 55 11 26 159 89 0
31 30 14 1 71 85 201 77 0
0 68 42 100 5 41 256 46 0
.. ... .. ... .. .. ... .. ...
24 87 1 37 17 78 220 65 3
45 100 45 35 37 2 219 67 3
55 1 13 30 55 67 166 83 3
32 51 79 93 52 1 276 35 3
40 31 71 63 92 97 354 7 3
[100 rows x 8 columns]
----------------------------------------
国語 数学 社会 理科 英語 合計 順位
クラス番号
0 57.16 50.60 51.76 50.56 48.92 259.00 48.72
1 51.48 51.60 51.72 61.08 38.60 254.48 45.24
2 44.80 44.88 50.84 47.80 54.40 242.72 51.64
3 50.56 42.32 50.80 48.28 42.68 234.64 55.72
----------------------------------------
標準偏差 : 3.1859669821938383
========================================
【試行2回目】
国語 数学 社会 理科 英語 合計 順位 クラス番号
63 3 8 79 19 0 109 98 0
78 24 99 61 54 55 293 24 0
8 52 7 1 85 25 170 81 0
32 51 79 93 52 1 276 35 0
4 67 76 87 68 80 378 4 0
.. .. .. .. .. .. ... .. ...
46 93 90 54 89 22 348 11 3
98 48 70 43 84 32 277 33 3
35 10 66 65 40 56 237 56 3
89 61 79 61 53 96 350 10 3
54 44 17 21 28 43 153 91 3
[100 rows x 8 columns]
----------------------------------------
国語 数学 社会 理科 英語 合計 順位
クラス番号
0 56.00 56.96 47.04 57.60 52.12 269.72 43.64
1 49.28 35.44 52.44 47.84 47.92 232.92 56.20
2 44.72 43.68 51.04 44.04 44.92 228.40 56.16
3 54.00 53.32 54.60 58.24 39.64 259.80 45.32
----------------------------------------
標準偏差 : 5.67094888586809
========================================
試行回数ごとに、成績表とクラスごと平均値のデータフレーム、バラツキ具合を示す標準偏差の値がちゃんと返ってきている。
メンバーもランダムに組み替えられている。グッジョブです。
クラス分け後のバラツキ具合を積み上げ棒グラフで見る
クラス別平均値の積み上げ棒グラフを、試行回数ごとに描きます。最終的な標準偏差が小さければクラス間のバラツキの押さえられた棒グラフになっているはずです。
ひとまず、クラス分け後のクラス別平均値データフレームから、クラス別の積み上げ棒グラフを描く関数を用意する。
# クラス別平均値積み上げ棒グラフ作成import matplotlib.pyplot as plt import japanize_matplotlib ##### クラス別の教科別平均値の積み上げ棒グラフ描画関数 #####defmake_graph(mean_df, i): """クラス別平均値データフレームmean_dfから積み上げ棒グラフを描画する""" fig, ax = plt.subplots(figsize=(15, 8), facecolor='w') mean_df.plot.bar(y=mean_df.columns[:5], ax=ax, stacked=True) plt.title('クラス別平均点積み上げ棒グラフ') plt.xticks(rotation=0, size=15) plt.grid() plt.xlabel('クラス名', size=12) plt.ylabel('教科別平均値とその合計') plt.savefig(f'試行{i+1}回目平均値積み上げ棒グラフ.jpg') plt.show()
できたので、for文でグラフ作図を回す。
##### 実行 ###### 成績表の生成 df = make_report() # クラス分けを3回繰り返すfor i inrange(3): classed_df, mean_df, _std = output_std(df) print(f'【試行{i+1}回目】') print(classed_df) print("標準偏差:", _std) make_graph(mean_df, i) print('='*40)
【試行1回目】
国語 数学 社会 理科 英語 合計 順位 クラス番号
88 29 87 9 75 86 286 24 0
81 49 81 78 75 54 337 12 0
9 90 89 62 66 58 365 4 0
63 84 57 82 1 54 278 28 0
50 95 17 32 0 96 240 52 0
.. .. ... .. .. .. ... .. ...
84 70 33 46 31 33 213 71 3
15 34 100 47 11 88 280 27 3
43 29 20 83 20 65 217 69 3
67 93 20 22 31 98 264 33 3
14 21 100 48 27 40 236 55 3
[100 rows x 8 columns]
標準偏差: 1.7814513761620392

========================================
【試行2回目】
国語 数学 社会 理科 英語 合計 順位 クラス番号
9 90 89 62 66 58 365 4 0
68 54 60 40 67 46 267 31 0
71 82 48 39 70 36 275 29 0
91 29 84 1 50 75 239 53 0
95 88 69 98 48 96 399 3 0
.. .. .. .. .. .. ... .. ...
34 59 30 16 24 42 171 86 3
21 87 18 45 94 9 253 46 3
16 73 37 40 54 26 230 60 3
8 81 48 47 89 39 304 18 3
20 7 83 54 52 18 214 70 3
[100 rows x 8 columns]
標準偏差: 3.3008540361357586

========================================
【試行3回目】
国語 数学 社会 理科 英語 合計 順位 クラス番号
34 59 30 16 24 42 171 86 0
58 31 86 11 44 62 234 57 0
35 67 42 5 81 88 283 25 0
32 24 37 29 13 27 130 98 0
69 29 79 16 54 27 205 73 0
.. .. .. .. .. .. ... .. ...
44 2 46 90 67 14 219 64 3
63 84 57 82 1 54 278 28 3
85 30 45 31 9 43 158 91 3
5 40 17 57 61 89 264 33 3
3 62 13 95 14 73 257 44 3
[100 rows x 8 columns]
標準偏差: 6.982852234342911
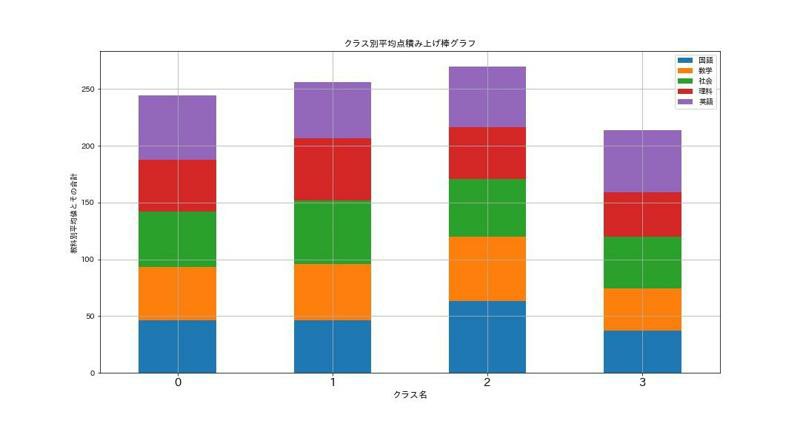
========================================
最終的な標準偏差の大きいクラス分けは、クラス間の平均点積み上げ高にも差が出てバラツキがある。
とはいえ、元々の成績表をnp.random.randint()の一様にランダムで作ったせいか、ランダムでシャッフルしてもそこまでクラス差はないような気が・・・
参考例として、
機械学習のk-means法(k-平均法)を使ったクラスタリングをやると偏ったクラス分けになる。
【Scikit-learn】k-平均法(k-means)を使って成績表からおまかせクラス編成する - よちよちpython
バラツキの抑えられたクラス分けが得られたとして、そのデータフレームを再現しなければならないが、ランダムを再現できないんだろう。
よって試行回数ごとに生成されているデータフレームを何らかの形で保存せねばならない。
次回はそこからにします。若干飽きてきましたww
以上です。
次回、最終回。
【Pandas】任意の教科数と人数の成績表から学力を平均的に指定数でクラス分けする - よちよちpython
追記
ランダム生成とセキュリティに関する話題。関連してそうなので貼ります。
これはひどい。『Kaspersky Password Managerが生成するパスワードは、random seedにシステムクロックを使ったせいで、作成された時間が大体わかれば時刻総ざらいでパスワードを簡単にBrute forceできる』とするThe Registerの記事。 https://t.co/jzJZWzXIoY
— Kazunori ANDO (@ando_Tw) 2021年7月7日